HITRAN 数据库用法
刘训臣
在上一篇 吸收光谱简介 ,我们介绍了分子吸收光谱的基本知识。 常见的分子光谱的数据库有:
- HITRAN, USA Harvard-Smithsonian Center for Astrophysics Molecular Data
- NASA JPL Molecular Spectroscopy, USA
- The Cologne Database for Molecular Spectroscopy, CDMS, Germany
- GEISA Spectroscopic Database, France
- Pacific Northwest National Labs Spectral Database, USA
- Ames Research Center Infrared Spectral Database of PAH, USA
- MPI-Mainz-UV-VIS Spectral Atlas of Gaseous Molecules, Germany
- surface types: US Geological Society Digital Spectral Laboratory, USA
- NIST Chemistry WebBook, USA
- AIST Integrated Spectral Data Base System for Organic Compounds, Japan
- Bremen, Institute of Environmental Physics, Germany
- LISA database (SCOOP), France
- Institute of Atmospheric Optics (CO2 O3), Tomsk, Russia
- Instituto Superior Tecnico SPATRAN, Gas and Plasma Radiation Database, Italy
HITRAN数据库是我们最常用的分子光谱谱线的数据库。NASA JPL 数据库中有很多星际分子的谱线,另外JPL数据库用的 SPCAT/SPFIT 软件也是功能非常强大。未来我们会尝试用 SPCAT 模拟高温反应流体的分子光谱。Tomsk 有很好的CO2的光谱数据库。
用HITRAN模拟一个吸收峰,我们参考 https://hitran.org/docs/definitions-and-units/ 中的定义。 需要光谱模型中的三个参数:
1)谱线位置,这需要吸收峰对应的上下能级的能级差,数据库给出了谱线位置和下能级,因此可以计算上能级位置;
2)谱线强度,定义如上篇文章给出 网页中公式4,HITRAN 数据库给出了参考温度下乘了同位素丰度的线强$S$,单位为$[\mathrm{cm^2 \cdot cm^{-1}}]$。
3)谱线展宽的线形,定义为Voigt展宽的线形,数据库给出了压力展宽的温度系数和展宽吸收
对于 每行160位的数据,可以用下面 python 代码读取每个跃迁的参数。
# HITRAN 160位格式读取函数
def read_hitran_par(filename):
"""
读取HITRAN 160位格式的par文件
返回格式: [波数, 线强, 爱因斯坦A系数, 空气加宽半宽, 自加宽半宽, 低态能量, 温度依赖系数, 压力位移]
"""
database = []
with open(filename, 'r') as f:
for line_num, line in enumerate(f, 1):
line = line.rstrip('\n') # 只去掉行尾换行符,保留其他空白
if len(line) < 160: # 确保行长度足够
print(f"警告: 第 {line_num} 行长度不足160字符,已跳过")
continue
try:
# 根据HITRAN格式定义解析各个字段
nu = float(line[3:15]) # 波数
S = float(line[15:25]) # 线强
A = float(line[25:35]) # 爱因斯坦A系数
gamma_air = float(line[35:40]) # 空气加宽半宽
gamma_self = float(line[40:45]) # 自加宽半宽
E = float(line[45:55]) # 低态能量
n_air = float(line[55:59]) # 温度依赖系数
delta_air = float(line[59:67]) # 压力位移
# 将解析的数据添加到数据库
database.append([nu, S, A, gamma_air, gamma_self, E, n_air, delta_air])
except ValueError as e:
print(f"解析第 {line_num} 行时出错: {repr(line)}")
print(f"错误信息: {e}")
continue
print(f"成功读取 {len(database)} 条谱线")
return np.array(database)
线宽模型的计算我们用Faddeeva 函数计算Voigt 线形。 Voigt 线型是Gaussian展宽(温度导致的速度展宽)和压力展宽的卷积,其中温度展宽的计算需要用到不同的分子同位素的质量。
压力展宽用的是数据库中的参数。
这里可以忽略 gamma_self 自展宽,复杂环境中各种分子的碰撞展宽太多了,就不考虑自展宽了。这样Voigt 线形可以只计算一次,大大节约计算时间。
注意这里用的是 CGS 单位制的物理常数。
# physical constants
T_ref = 296.0
cBolts = constants.Boltzmann*1E7 # CGS Boltzmann constant unit is erg/K, CGS, c is cm/s
cc = constants.speed_of_light*1E2 # CGS
cNA = constants.N_A
c2 = constants.physical_constants['second radiation constant'][0]*100 # CGS cm K
cP = constants.physical_constants['standard atmosphere'][0]*10 # pressure unit in CGS is Ba. covert to 0.1 Pa
##################################################################################
# Voigt lineshape from Faddeeva function
cGammaD = math.sqrt(2*cBolts*cNA*math.log(2))/cc
def profile_voigt(Mass,nu,gamma_air,n_air,delta_air,T,p,wavenumber): # return voigt profile on wavenumber, function of (T,p)
gamma = gamma_air*p*((T_ref/T)**n_air)#+gamma_self*p*c*((T_ref/T)**n_self) # Eqn 6
#gamma = gamma_air*gamma_air_ratio*p*(1-c)*((T_ref/T)**n_air)+gamma_self*p*c*((T_ref/T)**n_self) # Eqn 6
GammaD = cGammaD*math.sqrt(T/Mass)*nu# + laser # eqn (5),
sigma = GammaD/(math.sqrt(2*math.log(2)))
variable = (wavenumber- nu - delta_air*p+gamma*1j)/(sigma*math.sqrt(2)) # air shift
voigt = (special.wofz(variable)).real/(sigma*math.sqrt(2*constants.pi))
return voigt
接下来只需要数据库par 文件就可以一行一行的叠加计算了。 计算调用coef 吸收系数,OD 为乘了分子密度和吸收距离的光学厚度。coef 和 OD 可以线性叠加。
##################################################################################
# line-by-line coef calculation
def coef(Mass,T,p,database,partition_function,wavenumber):#,color): # k absorption coef
coef = np.zeros(len(wavenumber))
for line in database:
nu = line[0]
S = line[1]
gamma_air = line[3]
E = line[5]
n_air = line[6]
delta_air = line[7]
profile = profile_voigt(Mass,nu,gamma_air,n_air,delta_air,T,p,wavenumber)
intensity = S * partition_function[int(T_ref-1)]/partition_function[int(T-1)] * math.exp(-c2*E/T)/math.exp(-c2*E/T_ref)*(1-math.exp(-c2*nu/T))/(1-math.exp(-c2*nu/T_ref)) # Eqn 4, T is rounded
# ax1.bar(nu,peak,align='center',width=0.001,color='b')
coef += profile*intensity
return coef
def OD(Mass,T,p,c,l,database,partition_function,wavenumber): # optical density # k*[X]*l absorption coef times volume density, assuming total pressure p and c is pressure fraction. c needs to times length in unit cm to get dimensionless optical depth \tao, bkg is added at the end
acoef = coef(Mass,T,p,database,partition_function,wavenumber)
density = p*c*cP/(cBolts) /T # volumn density /cm^3 from p/kT # check if concentration change
OD = acoef*density*l
Tr = np.exp(-OD)
Ab = 1-Tr
return OD,Ab,Tr
完整的代码py 文件,读取 CO_1416.par 数据库文件和 q5.txt 配分函数文件。
借助deepseek,我们可以写一个更加完整的 hitran_spectrum.py 程序,可以读取par 文件后自动查找分子质量,自动给出 par 文件包括的波数范围(当然也可以给定波数范围)。
这里omega_wing参数参考了hapi 中的定义,只计算谱线周围10倍线宽范围。或者说离的很远的谱线吸收就可以忽略了。这在大的波数范围内计算节约时间。
这里运行 hitran_spectrum.py ,只需要读取par 文件和Q文件夹(其中是q1 q2 等所有的配分函数文件),程序就可以自己找到对应的分子数和同位素编号,找到对应的分子质量和配分函数。
还做了一个图形界面hitran_gui.py 。可以点击选择par 文件和Q文件夹,点击按钮读取数据;输入温度、浓度、长度、压力,就可以点击按钮计算并存文件了。
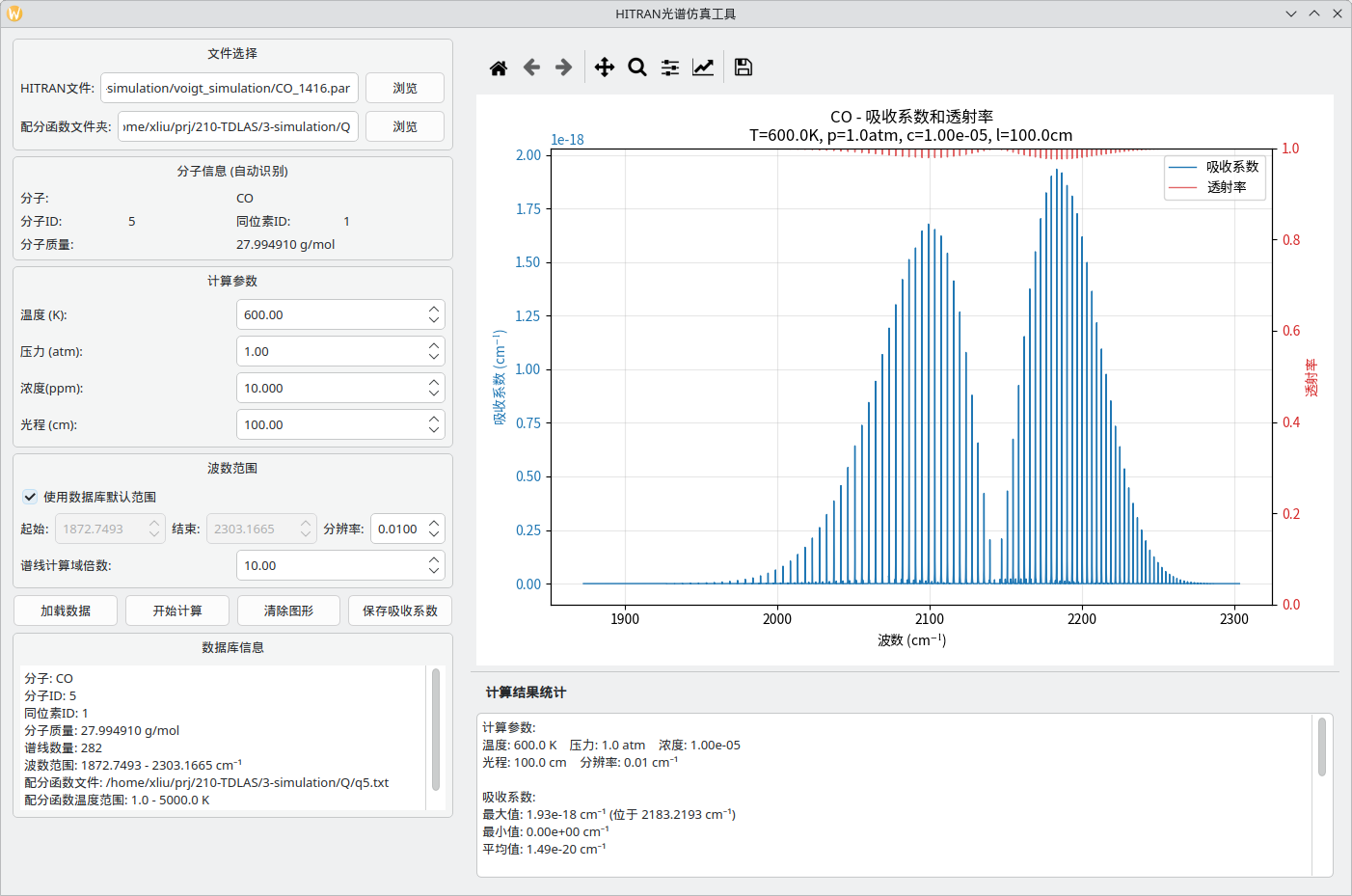
hitran_gui截图
两个py文件下载:
最新版py文件和数据库par 文件下载请看 光谱仿真
很多时候,不需要完整地计算par 文件中的每一行数据,只需要选择某一个同位素、或者某一个谱带。 这就只需要删除 par 文件中的行就可以了。这就需要vi emacs 等能选择字符匹配的文本编辑工具了。具体来说就不属于仿真软件的功能了(尽管hapi 中有比较好的选择工具,但用下来,还是感觉直接编辑par 文件更直接一些。)